2分鐘
FreeDV 與 RADEv2
前言
在這篇文章,我當時介紹基於機器學習的數位通訊模式 FreeDV 在此模式中有一個叫 RADEv1 的編碼格式,該技術採用了機器學習技術 (ML) 進行語音編碼,嘗試達到在相同的 SNR 下能比傳統 SSB 有著更好的通訊品質。
但是當時寫文章時, RADEv1 仍屬預覽版 (也就是測試階段) 所以軟體上面多少有些 Bug ;在經歷了快 1 年的時間,開發團隊放出了 FreeDV 2.0.1 正式版,在正式版中修復了大量的 Bug 也讓軟體更佳的穩定。

然而開發團隊並未就此打住。
RADEv1 的缺點
RADEv1 雖然提供了不錯的表現,但是有幾個缺點:
它的核心是使用 Python 來跑的 因為要跑 PyTorch 來進行推論,所以執行的效率比較差(尤其是低階的電腦),關於這點開發團隊開始著手進行軟體的移植,目前開發中的 RADEv2 基本上核心的程式碼已經改寫成 C 語言了;儘管如此現階段跑 RADEv1 仍需要用到 Python 的函式庫
訊號雜散問題 可能是作者當初設計時沒想到那麼多,在即時輸出的瀑布圖中,「黃色」的地方才是真正的訊號,而左右兩側則是多餘的;當發現這個問題的時候,作者本來有打算使用 BPF 的方式過濾掉,但是發現了會造成 RADEv1 解碼性能的下降,因此在二代的時候要重新構思。

RADEv2 開發的亮點
Using ML to handle phase distortion from the HF channel, fine frequency offsets, and small timing offsets (normally performed using classical DSP).
No pilot or unique word symbols which is pretty novel compared to any other waveform I’ve ever seen, (saving bandwidth and power, framing overheads).
Low latency frames of around 40 ms (very low for robust digital voice, supporting rapid PTT turn around, faster sync).
A 800 Hz 99% power occupied bandwidth (3x bandwidth efficiency of SSB). A PAPR of 3 dB through commodity SSB radio filters (this is pretty good for OFDM and compared to SSB, and we may be able to improve this further).
ML frame sync and fine timing (normally done with classical DSP, supports low overhead no pilot/UW operation).
Compared to RADE V1 (and most other modems), very little classical DSP code.
上面引用了作者發佈的文章,基本有解決 v1 版本的缺失,
在這張圖顯示了, RADEv1 與 RADEv2 波形的差別,簡單來說僅用了 800 Hz 的頻寬,來實作出比傳統 SSB 與 RADEv1 還要更低的頻率占用。
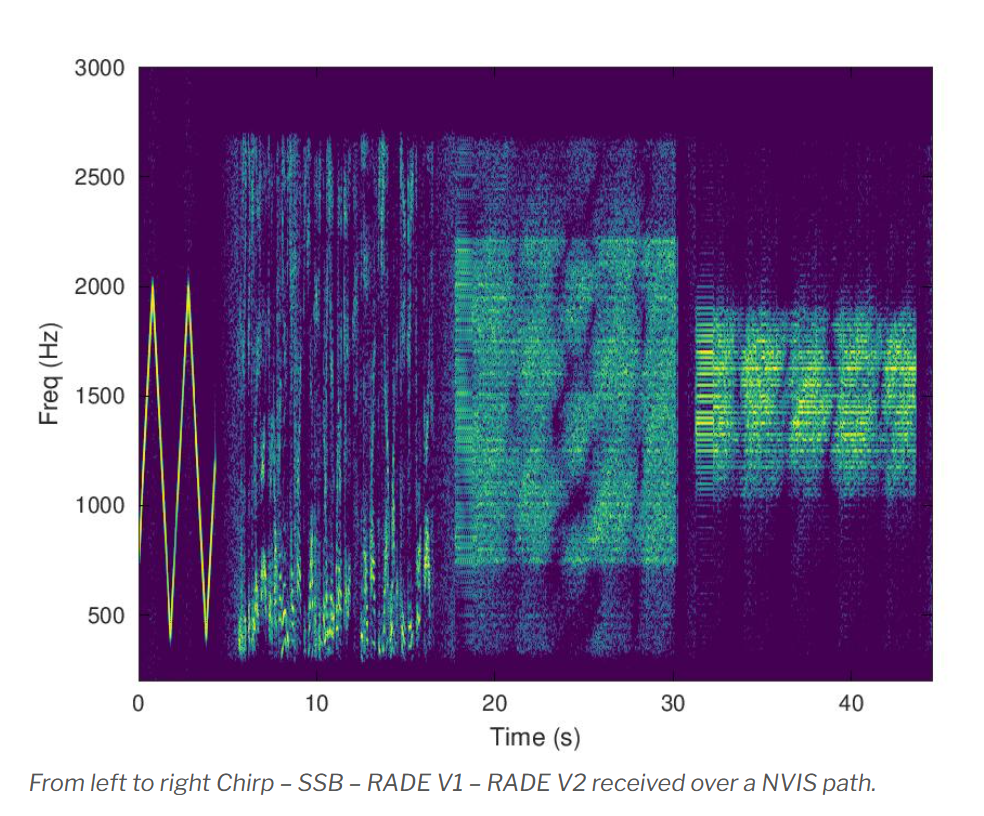
而面對瞬息萬變的短波環境,能提供更可靠的通訊品質。在剛剛提到的文章連結內,有著音質的 DEMO 比較,有興趣的友台可以去聽。
RADEv2 何時推出?
目前開發團隊沒有給出一個答案,在文章中現階段的表現作者仍不夠滿意,因此仍然在內部測試開發中,我會持續的關注這項領域的發展。
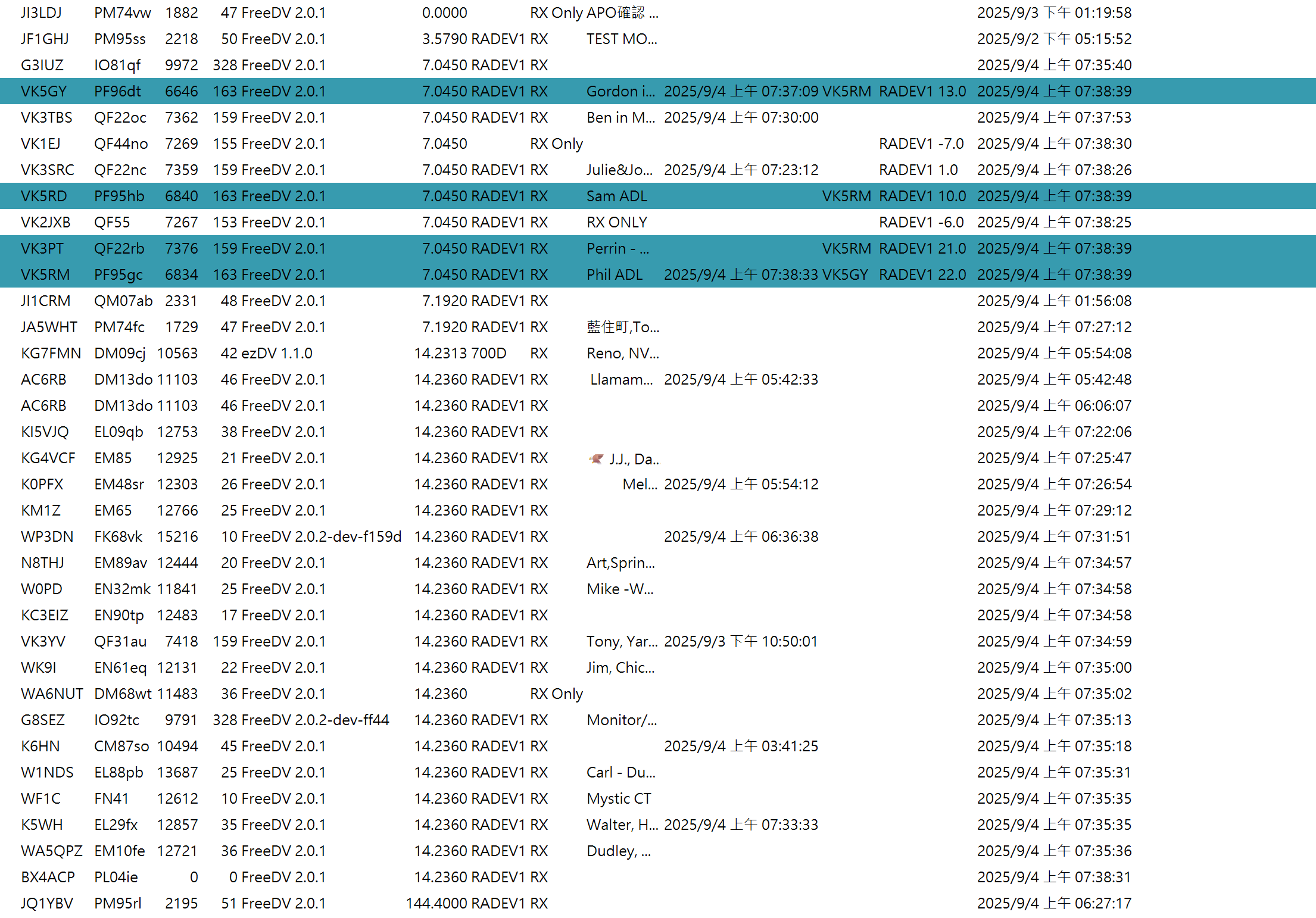
目前亞洲完這個模式的人多嗎?
由於 FreeDV 內建有回報功能,目前亞洲最活躍的國家是日本台,據筆者的觀察牠們時常透過 NVIS 的特性在日本境內進行 QSO 。
小結
期待 RADEv2 推出,有推出的消息我會跟大家講。